I have a Flask web application running on an AWS EC2. To save the bill, I want to stop the EC2 at 10:30 PM ET and start it next day at 6:30 AM ET every day automatically. So I set out to research and implement the solution to achieve this goal.
First of all, My application uses nginx web server, I find I need to run the following command in order to make sure nginx server will be restarted after the EC2 server reboot:
chkconfig nginx on
Secondly, I figured out I can use cron to automatically start my application after EC2 reboot. I put all commands needed to start my application in a shell script, then added in the cron:
$> crontab -l @reboot /u01/app/mysql/start_myapp.sh > /tmp/start_myapp.out 2>&1
Lastly, I had to find out a way to start/stop EC2. I googled and got this url:
https://aws.amazon.com/answers/infrastructure-management/ec2-scheduler/
It stated:
In 2016, the EC2 Scheduler was launched to help AWS customers easily configure custom start and stop schedules for their Amazon Elastic Compute Cloud (Amazon EC2) instances. In 2018, AWS launched the AWS Instance Scheduler, a new and improved scheduling solution that enables customers to schedule Amazon EC2 instances, Amazon Relational Database Service (Amazon RDS) instances, and more. We encourage customers to migrate to AWS Instance Scheduler for future updates and new features.
Quickly checking “AWS Instance Scheduler”, I can know it is a overkill for my simple case as I only have one EC2 at this moment for this need. So I decided I would just use “aws ec2 stop-instance” and “aws ec2 start-instance”. And my Windows desktop pc at home is typically up and running 24 hours, so i put the command in the bat file and used the Windows Task Scheduler to call the bat file.
The bat files looks like:
-- start_ec2.bat set AWS_ACCESS_KEY_ID=XXXXXXXXXXXXXXXX set AWS_SECRET_ACCESS_KEY=YxxxxxxxxxxxxxXXXXXLDs set region = us-east-1 c:\AWSCLI\aws.exe ec2 start-instances --instance-ids i-0xxxxxxxxxxxx4 -- stop_ec2.bat c:\AWSCLI\aws.exe ec2 stop-instances --instance-ids i-0xxxxxxxxxxxx4
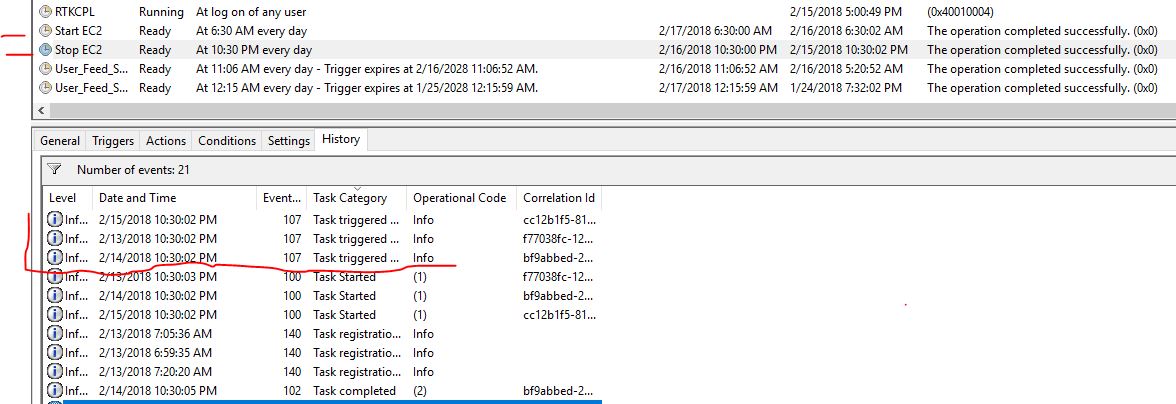
Below screenshot shows that the Stop EC2 task running successfully in the past three days. I did verify this solution works for my case.